As a longtime data engineer and data leader, I was excited to attend the Databricks Data + AI Summit this year in San Francisco. It was an exciting week of meeting people, experiencing what the community is working on, and learning about the advancements Databricks is making. Not surprisingly, many of the announcements were centered around advancements in AI. With their recent acquisition of MosaicML, Databricks is diving into the wonderful world of AI with both feet.
Before jumping into the announcements, some necessary background. Much of what I’ll discuss is based on a data lakehouse. A data lakehouse is a new data architecture that combines the flexibility, cost efficiency, and scale of data lakes, with the data management and transaction integrity of a data warehouse. This enables business intelligence and machine learning on all data. Data can be stored in a central location, moved quicker, and queried without having to access multiple systems.
Lakehouse IQ
The first keynote of the summit had a ton of new announcements and improvements. The first one that really grabbed my attention was the announcement of Lakehouse IQ. According to Databricks’ official announcement, Lakehouse IQ is “a knowledge engine that learns the unique nuances of your business and data to power natural language access to it, for a wide range of use cases. Any employee in your organization can use Lakehouse IQ to search, understand and query data in a natural language.” So, what does that mean, and how does it apply to your business? Well, instead of relying on a programmer with deep data knowledge, anyone who can log into Databricks can click a button to open the window, much like a chat assistant, and simply type a question such as “What were my sales in the north region in 2022?”
Lakehouse IQ learns your business terms and data concepts and uses that to answer these natural language questions. It takes these queues from across your business platform, including documents, Unity Catalog, and Dashboards. Databricks has provided this visual: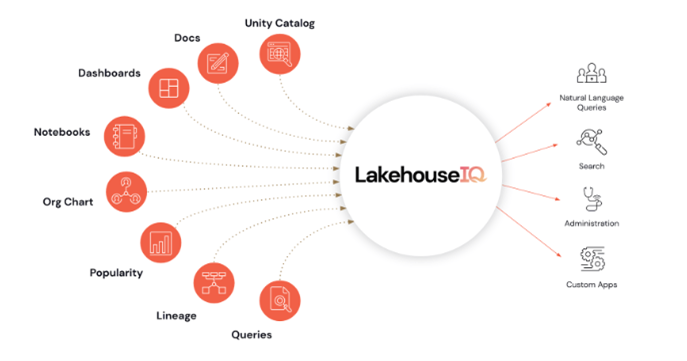
Unity Catalog: Data Lineage
I’d like to highlight Unity Catalog. Unity Catalog is an exciting Databricks product itself. In case you haven’t worked with it yet, Unity Catalog is a unified governance solution for all data assets in your data lakehouse. One of the newly announced capabilities is automated data lineage for workloads. Now, Unity Catalog will automatically track data lineage across queries executed in any language. That lineage is recorded to the table and column level. Key assets, such as notebooks and job are tracked. This advancement in lineage not only adds to your company’s enterprise data governance program, but also allows for assessing what the impact of changes made to a table will have on data consumers. Additionally, the data lineage enables auto-generating documentation, allowing consumers to better understand the data in the lake house.
Databricks has also added a built-in search capability. Once the data is registered in Unity Catalog, an end user can search across metadata fields including table names, column names, and comments, which are all important components often needed for analysis.
Accelerating Your Path to Data Science with Databricks
There is something to keep in mind as we read all of these announcements and get excited to integrate the new features into our lakehouses across the globe. The consistent aspect of all of these is a good, well-formed data lakehouse with clean data and properly configured and tagged in a Unity Catalog. The preparation for AI doesn’t happen overnight. Many organizations are excited to get into AI, but to do AI and do AI well, you need to have a plan, a roadmap. You need to identify what problems you are trying to solve, what your pain point is, and then identify how any of the Databricks products can solve that particular problem.
One of the advantages of working with Valorem Reply is that we are an Elite Databricks partner. We know this business as well as you know yours. So by working together, we can help you develop a roadmap specific to your business and use case, assess your position on the data maturity curve, and then guide you through the necessary steps to reach your goals.
If you’d like to learn more about how you can leverage data science to solve your use cases, check out our Databricks accelerators:
Advanced Demand Forecasting Accelerator: Improve your demand forecasting with predictive analytics and create a strategy to enable more accurate data-driven business decisions.
ERP Nitro Accelerator: Build a data warehouse for your SAP data and gain full control over your data & reporting.
